Github recently introduced hugely improved code search, one of those rare moments when a service I use adds a feature that directly and measurably measurably improves my life. Predictably, there was soon a flurry of breathless stories about the security implications. This shouldn't have been news to anyone - by now, it should be clear that better search in almost any context has security or privacy implications, a law of the universe almost as solid as the second law of thermodynamics. We saw this with Google's own code search, as well as Google proper, Facebook's Graph Search and even Bing. A certain fraction of people will always make mistakes, and and any sufficiently powerful search will allow bad guys to find and take advantage of the outliers.
After the dust had settled a bit I started wondering what else we could do with Github's search - other than snookering schmucks who checked in their private keys. I'm always enticed by data, and the combination of search and the ability to download raw checked-in files seemed like a promising avenue to explore. Lets see what we can come up with.
ghrabber - grab files from GitHub
First, some tooling. I've just released ghrabber, a simple tool that lets you grab all files matching a search specification from GitHub. Here, for instance, is an obvious wheeze - fetching all files with the extension ".key":
./ghrabber.py "extension:key"Downloaded files are saved locally to files named user.repository. Existing files with the same name are skipped, which means that you can reasonably efficiently stop and resume a ghrab.
Shell history files
I've been having a lot of fun exploring Github with ghrabber. I'll return to this in future posts - today I'll start with a quick illustration of what can be done. One type of difficult-to-find information that is sometimes checked in to repos is shell history. Two simple ghrabber commands for the two most popular shells is all we need:
./ghrabber.py "path:.bash_history"and
./ghrabber.py "path:.zsh_history"After cleaning the data a bit, I had 234 history files varying in length from 1 line to just over 10 thousand, containing a total of 165k entries. I fed this into Pandas for analysis, parsing each command using a combination of hand-hacked heuristics and the built-in shlex module. The remainder of this post is a light exploration of some approaches to this dataset, steering clear of the obvious and tediously well-covered security implications.
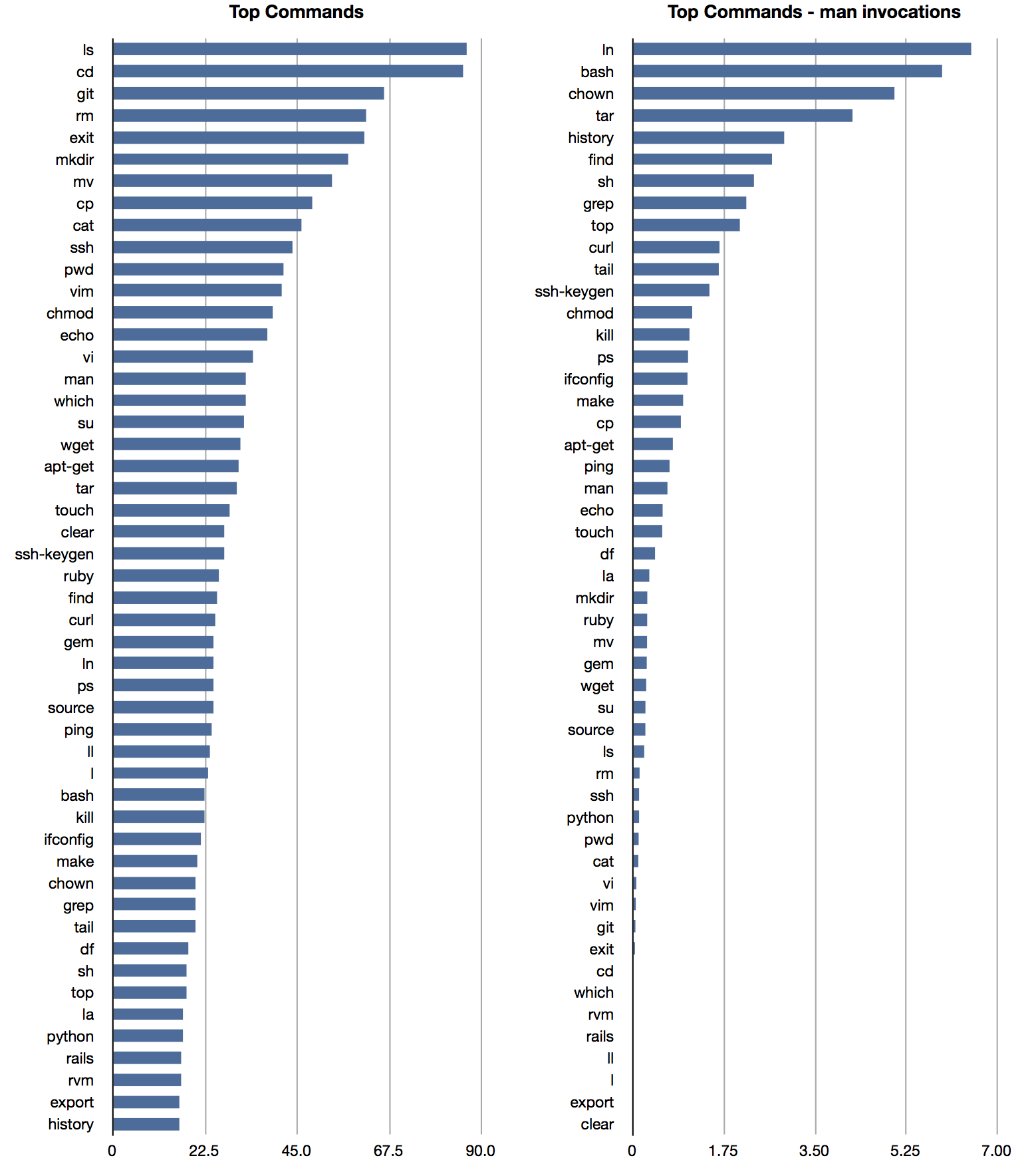
One way to slice the data is to look at the percentage of history files a given command appears in. This gives us a nice listing of the top commands by user prevalence, which you can see in the graph on the left above. On the right, I've taken the same list of commands, and checked how many invocations are preceded by a man lookup for the command. This gives us an idea of which commonly-used commands have difficult or unintuitive interfaces. It's interesting that ln is right at the top of the list, considering how simple the command syntax is. My theory is that everyone forgets the order of the source and target files.
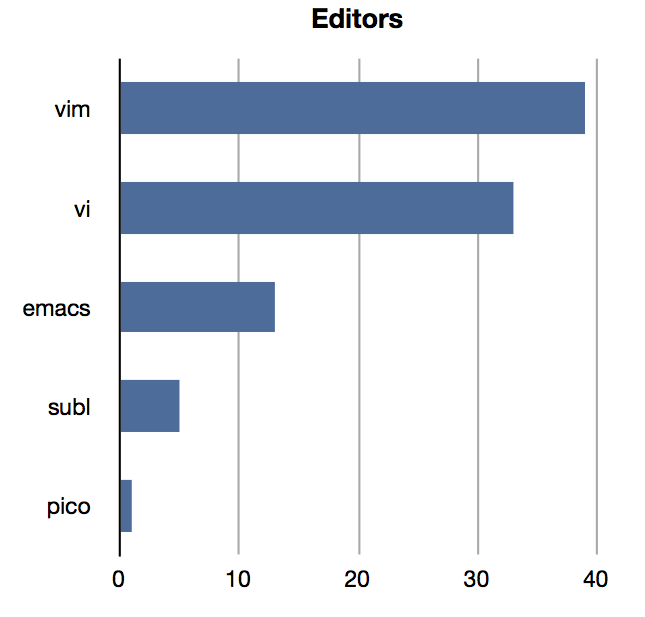
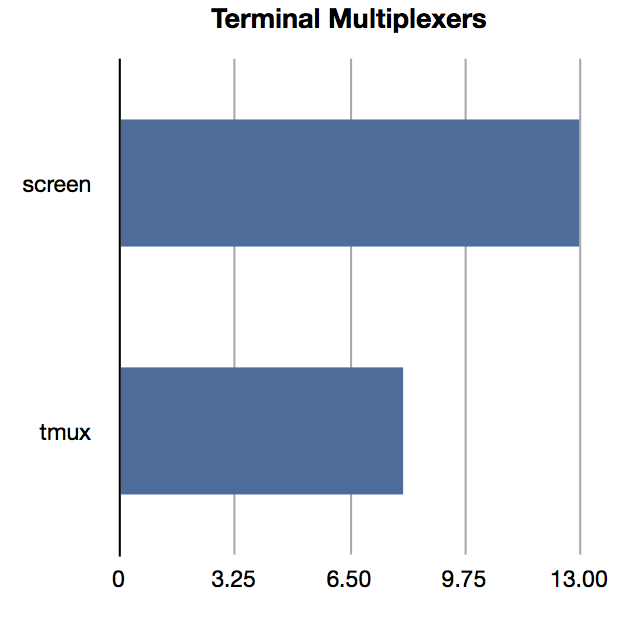
Since we have a list of the most widely used commands, it's also trivial to do silly popularity comparisons. Above is the obvious look at the state of the editor wars (vim is winning, folks), and a check on how tmux is doing in supplanting screen (the faster the better).
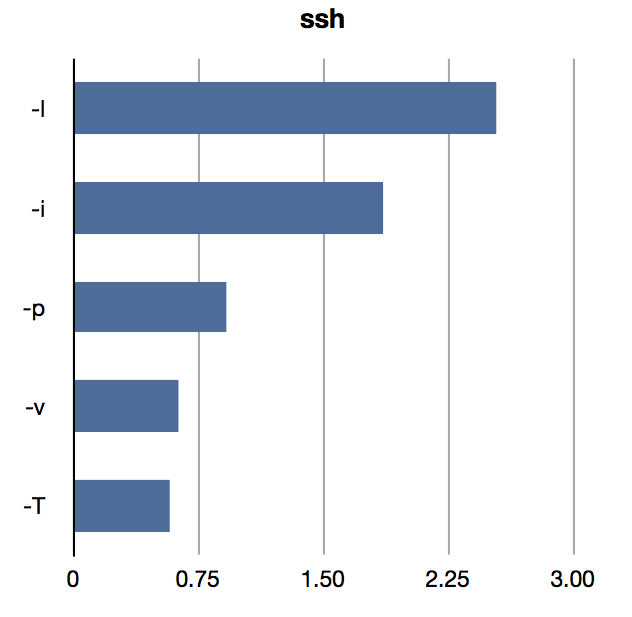
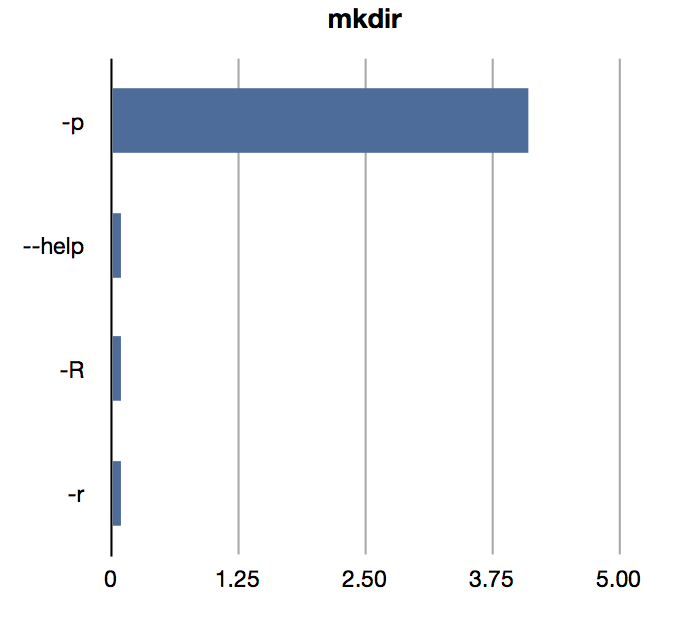
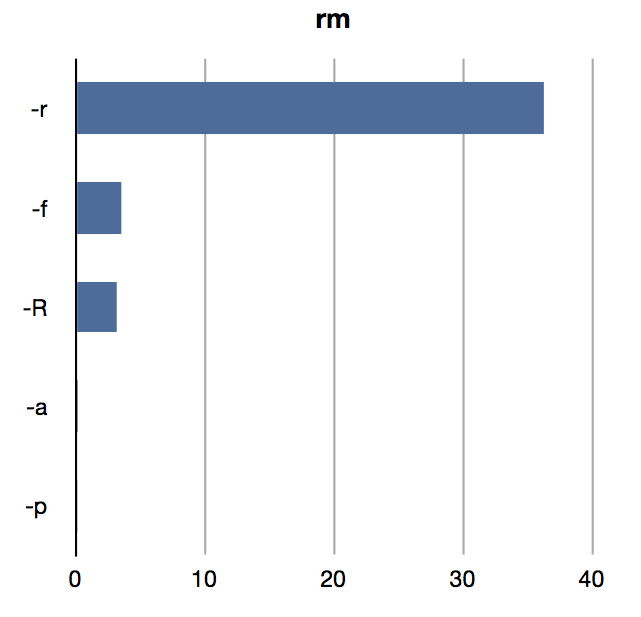
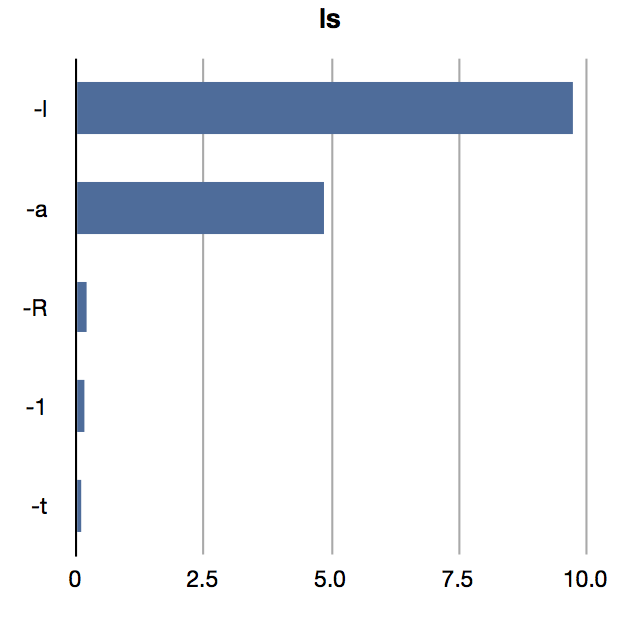
Another interesting thing to do is to look at the most commonly used flags to commands. I think having "real data" of command use may well guide us to design better command-line interfaces. I'd love to know the most common invocation flags for some of the tools I write.
I'll stop there. The data pool in this case is very deep, and there are a huge range of interesting bits of command-line ethnography that could be done. Stay posted for more in the coming weeks.