It's a universal rule that search over a sufficiently large body of user data poses security challenges. This follows naturally from the fact that humans - even smart, informed, careful humans - occasionally slip up. Given enough data, and the ability to pick out slip-ups with search, there will always be rich pickings for a malefactor. I wrote a short series of posts a while ago about interesting things I found on Github - commands from shell history files, common pipe chains, and words from custom spell-check dictionaries. While shell history files could definitely contain very sensitive information, in practice there were only a handful of really damaging issues in the dataset. Trawling around people's dotfile directories, I found that something much more damaging often made it into repos: browser state. It's easy to see how this could happen - it takes just one injudicious add of a hidden directory to expose cookies, browser history, bookmarks and more. I decided to return to this issue later, and it slipped off my radar until recently.
When I wrote the first series of posts, I also released a tiny tool called ghrabber (just a hack, really) that lets you grab files from Github en-masse using a Github code search query. The first thing I noticed when I picked it up again is that it no longer worked as expected. I used to be able to retrieve all files matching a path, like so:
ghrabber.py "path:.bash_history"Today, this returns an error - Github now requires you to specify both a search term and a path1. There are all sorts of possible explanations for this change, but I like to think that it's meant to prevent (or at least impede) exactly the kind of trawling I've been amusing myself with.
Let's say we want to search for Firefox browser profile cookies. These are stored in a SQLite file called "cookie.sql". Github doesn't index binary files for search, so we can't search for characteristic content in the file. Path specification is broken, so we can't search for the filename. Stumped, right? Not so fast - the cookie files live in a directory with a large number of associated non-binary files. If we could come up with a signature for one of these accompanying files, then we could download a path relative to the match to retrieve the cookie storage file itself. I quickly added a flag to do exactly this to ghrabber, and cooked up appropriate query strings to detect Firefox and Chrome browser profiles. I'll elide those here, for obvious reasons.
A look at the data
The result was 708 distinct browser profiles that included 33 364 bookmarks, and 88 013 cookies. Many of these profiles are actually intentional checkins - testing trusses, blank profiles and so forth. However, some totally unscientific manual sampling indicates that just less than half of these are probably genuine accidental checkins, containing private information.
Let's take a light, high-level look at the data. The figure below shows the percentage of profiles with cookies from each TLD:
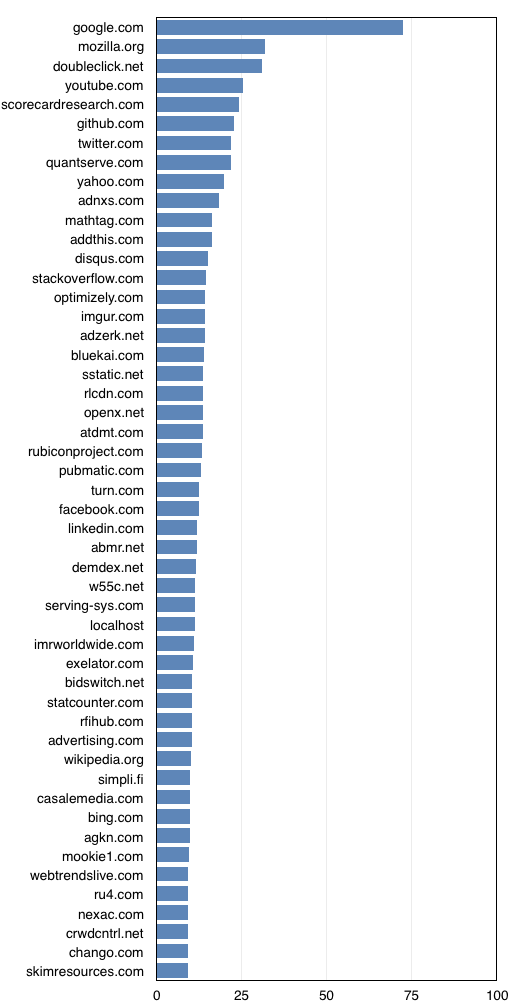
As expected, the stats here are dominated by the mega-trackers that infest almost every site on the internet - a familiar cast of rogues including DoubleClick, Scorecard Research, Quantserve and so forth. It's sad to see how few domains here are genuine destinations - apparently the top sites for this sample are Google, YouTube, Github (not unexpectedly), and Twitter.
Next up is the percentage of profiles with bookmarks for a given domain:

Here, the top domains are those pre-seeded on install, particularly with Firefox. This explains the Mozilla domains as well as ubuntu.com, debian.org and launchpad.net. Once we're outside of this list, the "genuine destinations" match the cookie dataset quite well - YouTube, Github, Wikipedia, and so forth.
A difficult situation
The surprise here is not that people accidentally check sensitive information into git repos. The real surprise is just how much of a pain in the butt it was to responsibly address the issue. At the end of this little experiment, I had more than 700 repositories that potentially contained sensitive, accidentally exposed user information. It beggars belief, but it's 2015 and the most popular repository hosting service in the world has no way to privately report a bug against a repo. One could create a public bug report for each repository in question - but that would be like hanging out a neon sign saying "privacy issue here" for others to find, particularly since bug reports are published in a user's activity stream.
In the end, I decided to directly notify as many people as I could by email. So, I wrote a script that checked each affected user's profile for an email address. That left me with 120-odd users with contact details. I manually whittled these down to repositories that were obviously accidental checkins and sent them each an email, resulting in a dozen or so responses with variations on "oops, thanks for letting me know".
Hey Github!
I have two recommendations for Github that would make this situation vastly, vastly better:
-
Add a mechanism that lets users report private bugs, visible only to the repo owners. There's just no excuse for the lack of a feature like this.
-
Consider restricting search functionality somewhat. One option would be not to index dotfiles (.*) by default, and perhaps let users opt in to dotfile indexing on a per-repo basis. The vast majority of accidental checkins are either within dotfiles (shell history, for example), or within directories that start with leading dots (browser history, ssh config)
In fact, Github search path specifications seem to be broken now in a more general way, but that's beside the point for this post.