Edit: Since this post, I've created an interactive tool for binary visualisation - see it at binvis.io
Last week, I wrote about visualizing binary files using space-filling curves, a technique I use when I need to get a quick overview of the broad structure of a file. Today, I'll show you an elaboration of the same basic idea - still based on space-filling curves, but this time using a colour function that measures local entropy.
Before I get to the details, let's quickly talk about the motivation for a visualization like this. We can think of entropy as the degree to which a chunk of data is disordered. If we have a data set where all the elements have the same value, the amount of disorder is nil, and the entropy is zero. If the data set has the maximum amount of heterogeneity (i.e. all possible symbols are represented equally), then we also have the maximum amount of disorder, and thus the maximum amount of entropy. There are two common types of high-entropy data that are of special interest to reverse engineers and penetration testers. The first is compressed data - finding and extracting compressed sections is a common task in many security audits. The second is cryptographic material - which is obviously at the heart of most security work. Here, I'm referring not only to key material and certificates, but also to hashes and actual encrypted data. As I show below, a tool like the one I'm describing today can be highly useful in spotting this type of information.
For this visualization, I use the Shannon entropy measure to calculate byte entropy over a sliding window. This gives us a "local entropy" value for each byte, even though the concept doesn't really apply to single symbols.
With that out of the way, let's look at some pretty pictures.
Visualizing the OSX ksh binary
In my previous post, I used the ksh binary as a guinea pig, and I'll do the same here. On the left is the entropy visualization with colours ranging from black for zero entropy, through shades of blue as entropy increases, to hot pink for maximum entropy. On the right is the Hilbert curve visualization from the last post for comparison - see the post itself for an explanation of the colour scheme. Click for larger versions with much more detail:


Note that this is a dual-architecture Mach-O file, containing code for both i386 and x86_64. You can see this if you squint somewhat at these images - some broad structures in the file are repeated twice. We can see that there are a number of different sections of the ksh binary that have very high entropy. It's not immediately obvious why a system binary would contain either compressed sections or cryptographic material. As it happens, the explanation in this case is quite interesting. Let's have a closer look:
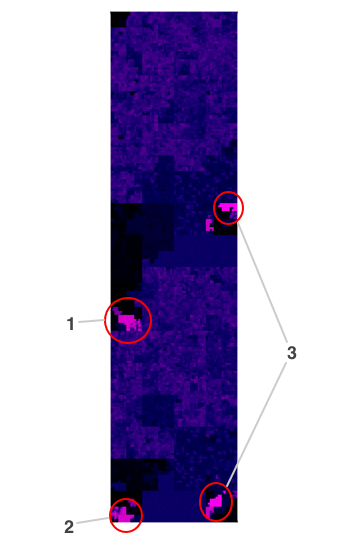
Sections 1 and 2 are a lovely validation of the central idea of this post. These two areas do indeed contain cryptographic material - in this case, code signing hashes and certificates. Rather satisfyingly, they stand out like a sore thumb. It turns out that all of the official OSX binaries are signed by Apple. This is then used in turn to apply a variety of policies, depending on who the signatory is, and whether they are trusted.
You can dump some rudimentary data about a binary's signature using the codesign command (which you can also use to sign binaries yourself):
> codesign -dvv /bin/ksh
Executable=/bin/ksh
Identifier=com.apple.ksh
Format=Mach-O universal (i386 x86_64)
CodeDirectory v=20100 size=5662 flags=0x0(none) hashes=278+2 location=embedded
Signature size=4064
Authority=Software Signing
Authority=Apple Code Signing Certification Authority
Authority=Apple Root CA
Info.plist=not bound
Sealed Resources=none
Internal requirements count=1 size=92Section 3 (the two occurrences are the same data repeated for each architecture) is interesting for a different reason - it's a cautionary example of how the simple entropy measure we're using sometimes detects high entropy in highly structured data. A hex dump of the start of the region looks like this:
000d1f00 00 01 00 00 00 02 00 00 00 06 00 00 00 00 00 00 |................|
000d1f10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000d1f20 00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f |................|
000d1f30 10 11 12 13 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f |................|
000d1f40 20 21 22 23 24 25 26 27 28 29 2a 2b 2c 2d 2e 2f | !"#$%&'()*+,-./|
000d1f50 30 31 32 33 34 35 36 37 38 39 3a 3b 3c 3d 3e 3f |0123456789:;<=>?|
000d1f60 40 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f |@ABCDEFGHIJKLMNO|
000d1f70 50 51 52 53 54 55 56 57 58 59 5a 5b 5c 5d 5e 5f |PQRSTUVWXYZ[\]^_|
000d1f80 60 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f |`abcdefghijklmno|
000d1f90 70 71 72 73 74 75 76 77 78 79 7a 7b 7c 7d 7e 7f |pqrstuvwxyz{|}~.|
000d1fa0 80 81 82 83 84 85 86 87 88 89 8a 8b 8c 8d 8e 8f |................|
000d1fb0 90 91 92 93 94 95 96 97 98 99 9a 9b 9c 9d 9e 9f |................|
000d1fc0 a0 a1 a2 a3 a4 a5 a6 a7 a8 a9 aa ab ac ad ae af |................|
000d1fd0 b0 b1 b2 b3 b4 b5 b6 b7 b8 b9 ba bb bc bd be bf |................|
000d1fe0 c0 c1 c2 c3 c4 c5 c6 c7 c8 c9 ca cb cc cd ce cf |................|
000d1ff0 d0 d1 d2 d3 d4 d5 d6 d7 d8 d9 da db dc dd de df |................|
000d2000 e0 e1 e2 e3 e4 e5 e6 e7 e8 e9 ea eb ec ed ee ef |................|
000d2010 f0 f1 f2 f3 f4 f5 f6 f7 f8 f9 fa fb fc fd fe ff |................|We see that this section contains each byte value from 0x00 to 0xff in order - furthermore this whole block is repeated with minor variations a number of times. There are two things to explain here - why is this detected as "high entropy" data, and what the heck is it doing in the file?
First, we need to understand that the Shannon entropy measure looks only at the relative occurrence frequencies of individual symbols (in this case, bytes). A chunk of data like the one above therefore looks like it has high entropy, because each symbol occurs once and only once, making the data highly heterogeneous.
Now, what earthly use would chunks of data like this be? With a bit of digging, I found the answer in the ksh source code. These sections are maps used for translation between various character encodings. If you're interested, here's the culprit in all its repetitive glory.
The code
As usual, the code for generating all of the images in this post is up on GitHub. The entropy visualizations were created with binvis, a new addition to scurve, my compendium of code related to space-filling curves.