Earlier this week I published ghrabber, a simple tool that lets you grab files matching an arbitrary search specification from GitHub. I used ghrabber to retrieve all the bash_history and zsh_history files accidentally checked in to repos, and took a light look at the dataset with some simple graphs. In total, I obtained 234 shell history files with 165k individual command entries. This is a very rare opportunity to "shoulder-surf", to actually see what people do at the command prompt, and perhaps get some insights into how to improve things.
Along those lines, today's post looks at pipe chains - that is, compound commands that pipe the output of one command to another. The pipe operator lies at the core of the Unix command-line philosophy. The fact that we can easily compose complex operations is the reason why we are able to write small tools that "do one thing well" without losing generality. The shell history data on Github can give us some real data about what people do with composed commands, and how they do it.
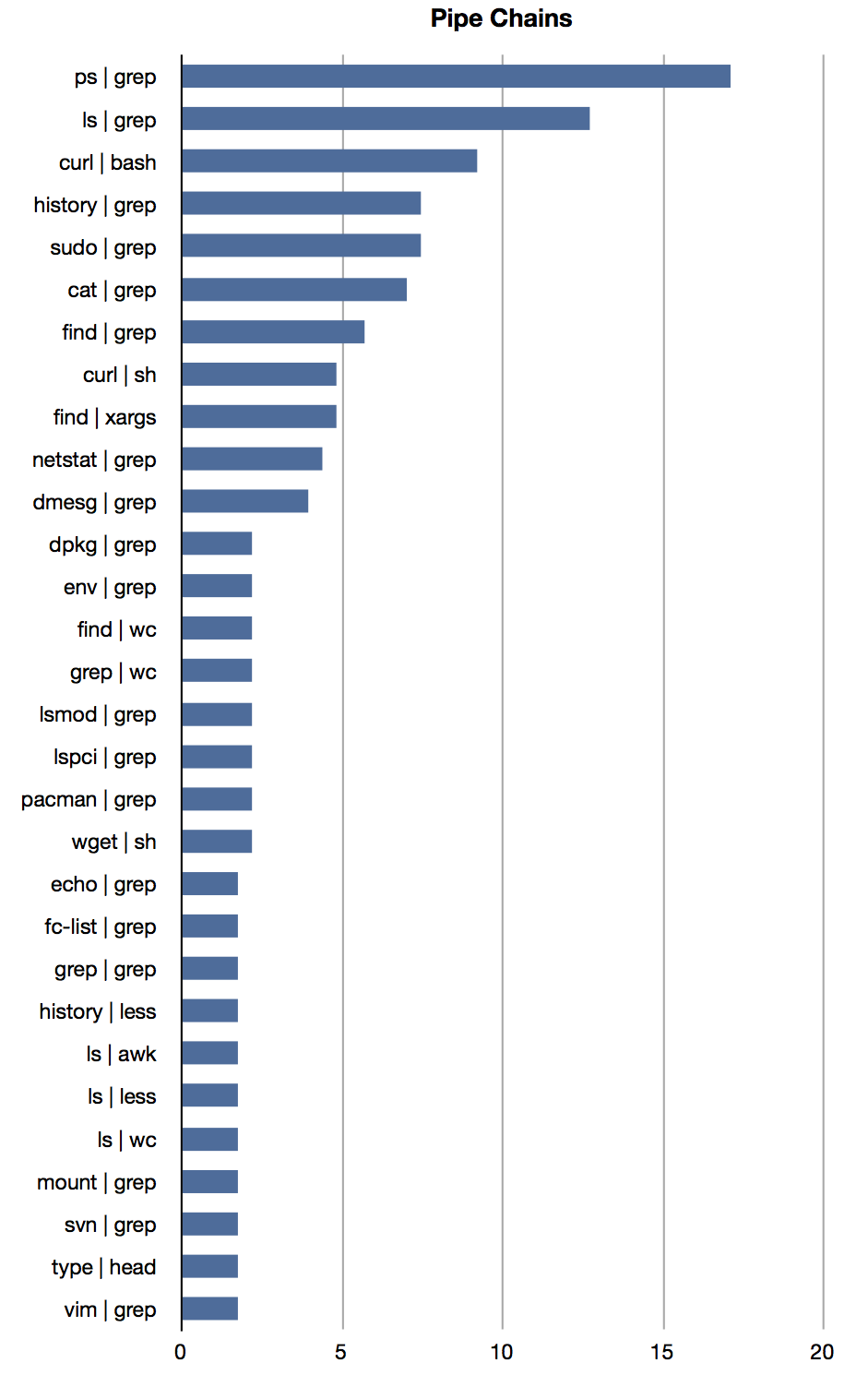
It turns out that about 2% of all commands issued on the command-line use pipes. The graph above shows the prevalence the most common pipe chains - that is, what percentage of the user in my sample used each chain. There's a lot of fascinating stuff we can read straight from this image.
Starting at the top, the first thing we notice is how widely used the ps | grep chain is. About 17% of users in my sample used this chain - given the type of data we have, the real-world prevalence would surely be higher still. I've just been extolling the virtues of small tools and composability, but in this case practicality should beat purity. I suggest that everyone should have a command-alias similar to this in their shell configuration:
alias pg="ps aux | grep"I've added this to my .zshrc today, and I've already used it twice.
Next up, we have the ls | grep pipes. The vast majority of uses here could actually be accomplished using the shell's filename generation mechanism. This ranges from simple redundancies like grepping for file extensions, to performing quite complex matching operations that could be done using the shell's advanced glob operations. I'm guilty of this myself - I rarely use features like recursive globbing, expansions using character ranges, case insensitive globbing, and so forth. I've brushed up on filename expansion for my chosen shell, and perhaps you should too.
The last thing I want to point out is a pattern that's genuinely dangerous - curl | bash, along with its cousins curl | sh and wget | sh. Unfortunately, this has become the recommended installation pattern for some tool - the vast majority of invocations here are for RVM and Yeoman. I don't think it's a good idea to pipe anything from the web straight into a local shell, but the situation is made particularly dire by the fact that almost half of these invocations are either over plain HTTP or explicitly turn certificate validation off.
I'll stop here, although there are interesting things to say about nearly every entry in the graph above. Next week, I'll move on from the shell history sample, look at some other juicy datasets extracted using ghrabber.