This is the second post in which I try to add some data to my nagging doubts about the technical news ecosystem. In my previous post, I showed off a visualisation of how the proggit front page changes over time. In this post, I take a look at the flip-side of the coin - what happens to a specific post as it passes through the short, fickle social news cycle? To do this, I'll take a deep dive into my own server logs, looking at a recent post of mine that appeared briefly on both Hacker News and proggit. I'd guess that nearly all posts follow more or less the same trajectory as they are extruded through the social news mill, so this should be interesting to more people than just me. At the risk of making things a bit dry and descriptive, I'm saving speculation and interpretation for a future post.
The scene is set at about 10pm New Zealand time, when I put the finishing touches to my blog post, and fire off an rsync up to my server. I quickly double-check that the blog and the RSS feed have updated OK, tweet a link to the post, and go to bed. While I sleep, the post creeps onto both Hacker News and proggit, ultimately getting 41000 hits over the next 5 days or so. The graphs below show only the first 50 hours of the post's lifetime - everything after that is just a long, slow dénouement as it dwindles into obscurity.
Our real-time robot overlords
The action starts almost as soon as I click the "tweet" button. Within seconds, the post is retrieved by Twitterbot. One second later, Googlebot appears, and almost simultaneously I get hit by Jaxified, Njuice, LinkedIn and PostRank. In all, 10 bots read my blog post within the first minute, handily beating the first human, who slouches lethargically into view at a tardy 90 seconds.
Below is a list of the bots that retrieved my post before the first submission to a social news site. These are the realtime robots, presumably hoovering up the Twitter firehose and indexing all the links they find. The cast of characters is a mixture of the expected big fish, stealth startups, and skunkworks projects at well-known companies. Bot identity was gleaned from HTTP user-agent headers when they were provided, or by checking the ownership of the responsible IP through reverse DNS resolution and whois lookups when they weren't. Most of the real-time bots were well behaved, identifying themselves clearly with a URL in the user-agent string.
| minutes after publication | bot |
|---|---|
| 1 | |
| Jaxified | |
| NJuice | |
| PostRank | |
| Unidentified bot from a Microsoft-owned IP | |
| Yahoo! Slurp | |
| Unidentified bot from a BBC RAD labs IP. | |
| OneRiot | |
| 2 | FriendFeed |
| Kosmix | |
| Topsy Butterfly | |
| Unidentified bot from marban.com subdomain. (PoPUrls?) | |
| 3 | metauri.com |
| msnbot | |
| 6 | Summify |
| Bot identifying itself just as "NING", can't confirm that it's the Ning. | |
| 9 | tineye |
| 26 | spinn3r.com |
| 27 | backtype.com |
| 47 | facebookexternalhit |
Enter the heavyweights: Hacker News and Reddit
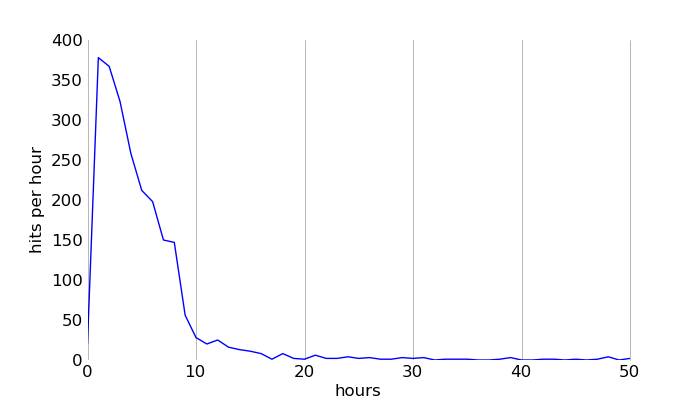
48 minutes after the post was published, the first hit from a social news site appears: hello Hacker News. The post quickly makes it onto the front page, and HN traffic peaks at 399 hits per hour in the second hour after publication. All told, the post got 2337 hits with a HN referrer header.
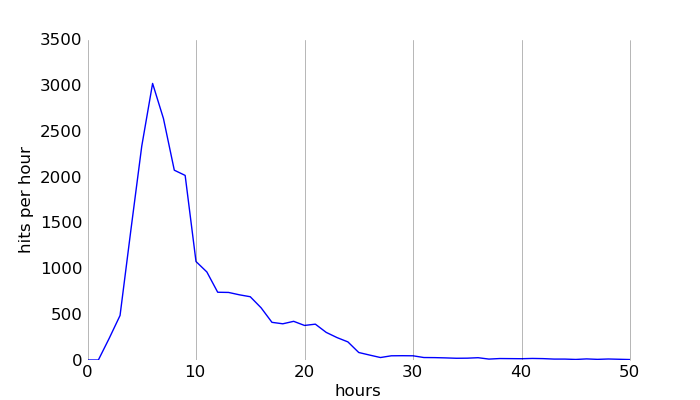
Two hours and three minutes after publication, the real monster of social news arrives: the first hit from Reddit appears. The Reddit traffic peaks in the sixth hour after publication at 3025 hits per hour, and delivers a total of 23807 hits in the 51 hours after publication.
The long tail
Reddit accounted for the vast majority of the post's traffic, dwarfing all other sources combined. In all, I received only 2300 hits with specified referrer headers that weren't Reddit or HN. Here are all the referrers that were responsible for more than 10 hits to the post:
| hits | site |
|---|---|
| 456 | popurls.com |
| 359 | Google Reader |
| 282 | |
| 196 | jimmyr.com |
| 183 | delicious |
| 153 | pop.is |
| 139 | Google Search |
| 82 | wired.com |
| 56 | |
| 36 | longurl.com |
| 36 | glozer.net/trendy |
| 30 | oursignal.com |
| 28 | hackurls.com |
| 24 | Yahoo Pipes |
| 18 | www.netvibes.com |
| 15 | dzone.com |
| 11 | www.freshnews.org |
It's interesting to see that I got nearly 200 hits from delicous.com. By contrast, pinboard.in - which seems to be delicous.com's anointed successor - sent me only two hits. Then again, my post was published in late November 2010, about a month before Yahoo spectacularly hobbled their bookmarking property. I wonder what those figures would look like today.
The thin end of the long tail are the 200 hits from 94 sites that were responsible for 10 or fewer hits each. We can break this motley crew up into a few different classes:
- Sites that provide some sort of social news analysis, piggy-backing off HN, Reddit and delicious.com. For example, popacular.com, seesmic.com, hotgrog.com.
- URL shorteners like j.mp and unshorteners like untiny.me
- Social media-ish services like FriendFeed, StumbleUpon, pinboard.in
- Tiny personal blogs.
- And, surprisingly - a number of sites that just provide an alternative interface or URL for Hacker News: hackerne.ws, ihackernews.com, hacker-newspaper.gilesb.com, www.icombinator.net.
Robot scavengers of the social news ecosphere
Let's take a look at overall bot traffic, separating out our silicone friends by looking for non-human and non-standard user-agent headers. The moment the post hits the HN front page bot traffic spikes, and this spike continues as the post is submitted to Reddit and starts its climb up the proggit front page.
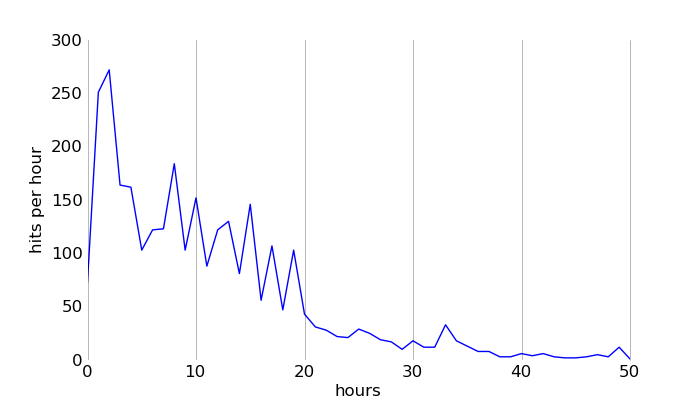
Enter the robot scavengers of the social news ecosphere - a set of second-tier aggregators that monitor social news and Twitter for hot stories. Here's a sample of bot visitors, taken more or less at random from the logs:
At this point, I'd like to bitch a bit about how astonishingly badly behaved some of the automated systems skulking around today's web are. The vast, vast majority don't provide any clue about the responsible entity in the user-agent string. The list above consists of responsible bots that do identify themselves, and less responsible ones that I could identify through reverse domain resolution. Most of the irresponsible bots come from Amazon Web Services, which seems to be a right wretched hive of scum and villainy. The worst performers here boggle the mind - about a dozen hosts from AWS retrieved the blog post more than 200 times a day, all using full GET requests, without an If-Modified-Since header, and with no identification. The arch-villain hit the post 600 times in its first 24 hours - that's about once every 2.5 minutes.
Referrer-less viewers and stealthy bots
I was surprised to see that almost 20% of requests not identified as bot requests had no specified referrer, a much greater percentage than I would have anticipated. Here's a graph showing the number of referrer-less requests per hour:
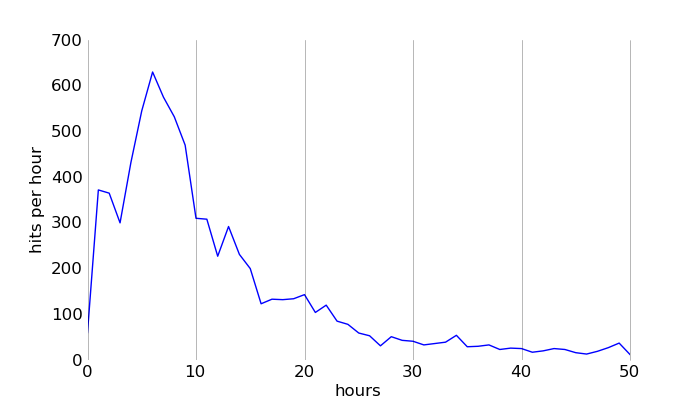
It looks like the double-peak in this graph coincides with the traffic peaks from HN and Reddit. This suggests that the majority of these hits do in fact come (perhaps indirectly) from HN and Reddit users. One possibility is that a chunk of this referrer-less traffic comes from non-browser Twitter clients.
A fraction of the referrer-less traffic also comes from stealthy bots sending user-agent strings that match those of desktop browsers. About 5% of these requests, for example, come from the Amazon EC2 cloud, so are unlikely to be real browsers. One Internet darling that does this is Instapaper, which seems to use the requesting client's user-agent string rather than frankly confessing itself to be a bot. It also appears to re-request an article in full for each user, rather than simply checking if there's been a change and using a cached copy. On the upside, this means that I know that 131 readers used Instapaper to view my post.
Aftermath
After the post drifts off the proggit and HN front pages, traffic dies down. There's a dwindling tail of stragglers that bothered to flip through to the second or third page of top stories, and a tiny dribble of users who discovered the link through other sources. A month later, the post gets about 60 hits per day, of which more than a third are from bots. Non-bot traffic is still dominated by Reddit, presumably from people searching or idly flicking through Reddit's history.
So, in the end, after my once-thrumming server quiets down, what has the lasting effect been on my own social graph? I had a small surge of Twitter follows, going from 230 to 245 followers. There was a minor blip of subscribers to my RSS feed, with Google Reader reporting subscriptions going from about 510 to 551. Out of 33,000 unique visitors 56 decided to cultivate a more permanent relationship of some sort to my blog. That's 1 in 600. If you remember only one figure from this post, this should be it.